
OctoML راه اندازی OctoAI، یک سرویس محاسباتی خودبهینه سازی برای هوش مصنوعی است
به گزارش سایت نود و هشت زوم OctoML راه اندازی OctoAI، یک سرویس محاسباتی خودبهینه سازی برای هوش مصنوعی است
که در این بخش به محتوای این خبر با شما کاربران گرامی خواهیم پرداخت
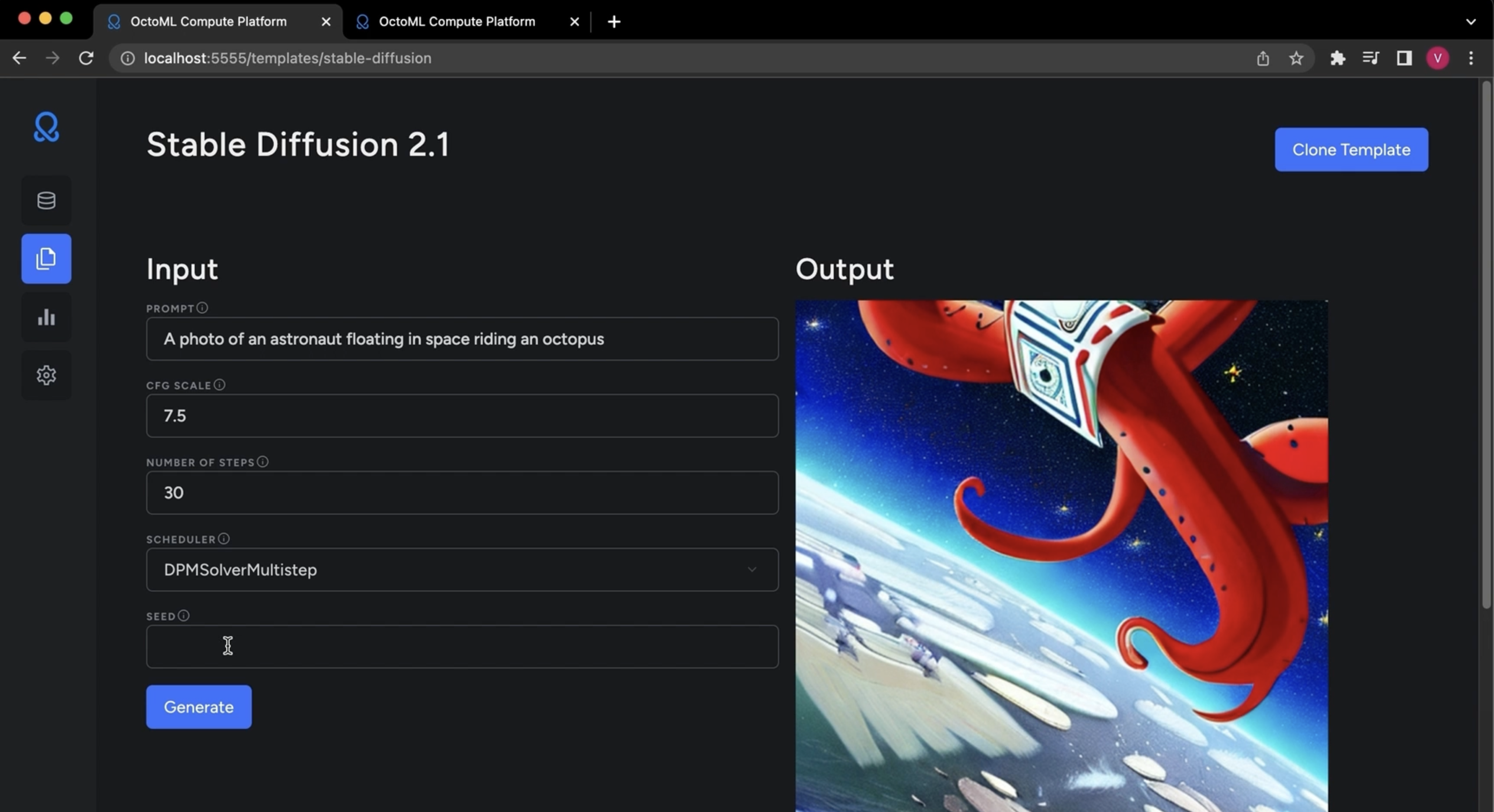
هنگامی که OctoML در سال 2019 راه اندازی شد، تمرکز اصلی آن بهینه سازی مدل های یادگیری ماشین (ML) بود. از آن زمان، این شرکت ویژگی هایی را اضافه کرده است که استقرار مدل های ML را آسان تر می کند (و 132 میلیون دلار جمع آوری کرده است). امروز، این شرکت در حال راهاندازی آخرین نسخه از سرویس خود است – و با اینکه کاملاً محوری نیست، تأکید شرکت را از بهینهسازی مدلها به کمک به کسبوکارها در استفاده از مدلهای منبع باز موجود و تنظیم دقیق آنها با دادهها یا استفاده از خود تغییر میدهد. این سرویس میزبان مدل های سفارشی خود است. پلتفرم جدید OctoML – با نام OctoAI – یک سرویس محاسباتی خودبهینهسازی برای هوش مصنوعی است، با تاکید ویژه بر هوش مصنوعی مولد، که به کسبوکارها کمک میکند تا برنامههای مبتنی بر ML بسازند و بدون نگرانی در مورد زیرساختهای زیربنایی، آنها را تولید کنند.
لوئیس سِز، یکی از بنیانگذاران و مدیرعامل OctoML توضیح داد: «پلتفرم قبلی بر مهندسین ML و بهینهسازی و بستهبندی مدلها در کانتینرهایی متمرکز بود که میتوانستند در مجموعههای مختلف سختافزار مستقر شوند. ما چیزهای زیادی از آن یاد گرفتیم، اما تکامل طبیعی بعدی این است که یک سرویس محاسباتی کاملاً مدیریت شده داشته باشیم که همه اینها را خلاصه کند. [ML infrastructure] دور.”
اعتبار تصویر: OctoML
با OctoAI، کاربران به سادگی تصمیم می گیرند که چه چیزی را می خواهند اولویت بندی کنند (تأخیر در مقابل هزینه فکر کنید) و OctoAI به طور خودکار سخت افزار مناسب را برای آنها انتخاب می کند. این سرویس همچنین بهطور خودکار این مدلها را بهینهسازی میکند (که منجر به صرفهجویی در هزینه و افزایش عملکرد میشود) و تصمیم میگیرد که آیا بهتر است آنها را روی پردازندههای گرافیکی Nvidia یا ماشینهای Inferentia AWS اجرا کنید. این بسیاری از پیچیدگیهای تولید مدلها را از بین میبرد، چیزی که هنوز اغلب سد راه بسیاری از پروژههای ML است. کاربرانی که میخواهند کنترل کاملی بر نحوه اجرای مدلهای خود داشته باشند، البته میتوانند پارامترهای خود را نیز تعیین کنند و تصمیم بگیرند که روی کدام سختافزار اجرا شوند. با این حال، Ceze معتقد است که اکثر کاربران ترجیح می دهند به OctoAI اجازه دهند همه اینها را برای آنها مدیریت کند.

اعتبار تصویر: OctoML
همچنین کمک میکند که OctoML نسخههای تسریعشدهای از مدلهای فونداسیون محبوب مانند Dolly 2، Whisper، FILM، FLAN-UL2 و Stable Diffusion را با مدلهای بیشتری در راه ارائه دهد. OctoML موفق شد که Stable Diffusion را سه برابر سریعتر اجرا کند و در مقایسه با اجرای مدل وانیلی، هزینه را تا 5 برابر کاهش دهد.
شایان ذکر است که در حالی که OctoML به کار با مشتریان فعلی که فقط میخواهند از این سرویس برای بهینهسازی مدلهای خود استفاده کنند، ادامه میدهد، تمرکز شرکت در آینده روی این پلت فرم محاسباتی جدید خواهد بود.
امیدواریم از این مقاله مجله نود و هشت زوم نیز استفاده لازم را کرده باشید و در صورت تمایل آنرا با دوستان خود به اشتراک بگذارید و با امتیاز از قسمت پایین و درج نظرات باعث دلگرمی مجموعه مجله 98zoom باشید
لینک کوتاه مقاله : https://5ia.ir/Ndwoxy
 t_98zoom@ به کانال تلگرام 98 زوم بپیوندید
t_98zoom@ به کانال تلگرام 98 زوم بپیوندیدکوتاه کننده لینک
کد QR :







آخرین دیدگاهها