
MLCommons پلتفرم جدیدی را برای محک زدن مدل های پزشکی هوش مصنوعی راه اندازی می کند
به گزارش سایت نود و هشت زوم MLCommons پلتفرم جدیدی را برای محک زدن مدل های پزشکی هوش مصنوعی راه اندازی می کند
که در این بخش به محتوای این خبر با شما کاربران گرامی خواهیم پرداخت
با این همه گیری که به عنوان یک شتاب دهنده عمل می کند، صنعت مراقبت های بهداشتی مشتاقانه از هوش مصنوعی استقبال می کند. بر اساس یک نظرسنجی در سال 2020 توسط Optum، 80٪ از سازمان های مراقبت های بهداشتی یک استراتژی هوش مصنوعی دارند، در حالی که 15٪ دیگر در حال برنامه ریزی برای راه اندازی یک استراتژی هستند.
فروشندگان – از جمله شرکت های بزرگ فناوری – برای پاسخگویی به تقاضا در حال افزایش هستند. گوگل اخیراً از Med-PaLM 2، یک مدل هوش مصنوعی که برای پاسخ به سوالات پزشکی و یافتن بینش در متون پزشکی طراحی شده است، رونمایی کرد. در جاهای دیگر، استارت آپ هایی مانند هیپوکراتیک و OpenEvidence در حال توسعه مدل هایی برای ارائه توصیه های عملی به پزشکان در این زمینه هستند.
اما از آنجایی که مدلهای بیشتری که برای موارد استفاده پزشکی تنظیم شدهاند، به بازار میآیند، دانستن اینکه کدام مدلها – در صورت وجود – مطابق تبلیغات عمل میکنند، به طور فزایندهای چالش برانگیز میشود. از آنجایی که مدلهای پزشکی اغلب با دادههای محیطهای بالینی محدود و باریک (مثلاً بیمارستانها در امتداد ساحل شرقی) آموزش داده میشوند، برخی نسبت به جمعیتهای خاص بیماران، معمولاً اقلیتها، تعصب نشان میدهند – که منجر به اثرات مضر در دنیای واقعی میشود.
MLCommons، کنسرسیوم مهندسی متمرکز بر ساخت ابزارهای معیارهای صنعت هوش مصنوعی، در تلاش برای ایجاد یک روش قابل اعتماد و قابل اعتماد برای معیار و ارزیابی مدلهای پزشکی، یک پلت فرم آزمایشی جدید به نام MedPerf را طراحی کرده است. MLCommons میگوید MedPerf میتواند مدلهای هوش مصنوعی را بر روی «دادههای پزشکی دنیای واقعی متنوع» ارزیابی کند و در عین حال از حریم خصوصی بیمار محافظت کند.
الکس کارگیریس، رئیس مشترک گروه کاری پزشکی MLCommons، که رهبری MedPerf را بر عهده داشت، در بیانیهای گفت: «هدف ما استفاده از معیار بهعنوان ابزاری برای تقویت هوش مصنوعی پزشکی است. “آزمایش علمی و خنثی مدلها بر روی مجموعههای دادهای بزرگ و متنوع میتواند اثربخشی را بهبود بخشد، سوگیری را کاهش دهد، اعتماد عمومی ایجاد کند و از انطباق با مقررات حمایت کند.”
MedPerf، نتیجه یک همکاری دو ساله به رهبری گروه کاری پزشکی، با نظرات صنعت و دانشگاه ساخته شد – طبق گفته MLCommons، بیش از 20 شرکت و بیش از 20 موسسه دانشگاهی بازخورد دادند. (اعضای گروه کاری پزشکی شامل گروههای بزرگی مانند گوگل، آمازون، آیبیام و اینتل و همچنین دانشگاههایی مانند بریگهام و بیمارستان زنان، استنفورد و MIT هستند.)
برخلاف مجموعههای معیار سنجش هوش مصنوعی MLCommons، مانند MLPerf، MedPerf برای استفاده توسط اپراتورها و مشتریان مدلهای پزشکی – سازمانهای مراقبتهای بهداشتی – طراحی شده است تا فروشندگان. بیمارستانها و کلینیکها در پلتفرم MedPerf میتوانند مدلهای هوش مصنوعی را در صورت تقاضا ارزیابی کنند، از «ارزیابی فدرال» برای استقرار مدلها از راه دور و ارزیابی آنها در محل استفاده کنند.
MedPerf علاوه بر مدلها و مدلهای خصوصی که فقط از طریق API در دسترس هستند، از کتابخانههای معروف یادگیری ماشین پشتیبانی میکند، مانند مواردی که از Epic و خدمات OpenAI Azure مایکروسافت ارائه میشوند.
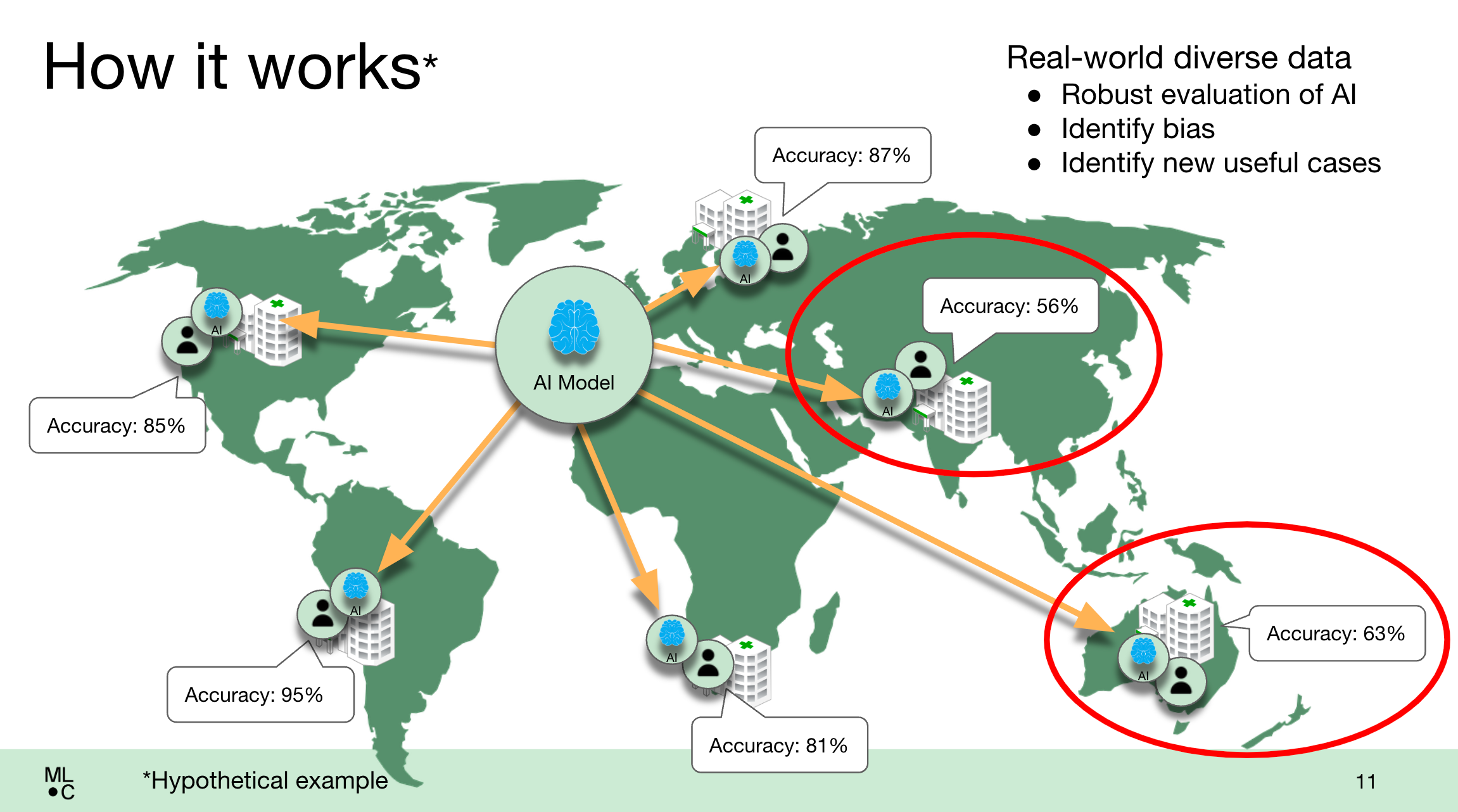
تصویری از نحوه عملکرد پلت فرم MedPerf در عمل. اعتبار تصویر: MLCommons
در آزمایشی از این سیستم در اوایل سال جاری، MedPerf میزبان چالش تقسیمبندی تومور فدرال (FeTS) با بودجه NIH بود، مقایسهای بزرگ از مدلها برای ارزیابی درمان پس از عمل برای گلیوبلاستوما (تومور تهاجمی مغز). MedPerf امسال از آزمایش 41 مدل مختلف پشتیبانی کرد که هم در محل و هم در فضای ابری در 32 سایت مراقبت های بهداشتی در شش قاره اجرا می شوند.
طبق گفته MLCommons، همه مدلها در سایتهایی با جمعیتشناختی بیماران متفاوت از مواردی که در آن آموزش دیدهاند، عملکرد کاهشیافتهای را نشان دادند و سوگیریهای موجود در آن را آشکار کرد.
رناتو اومتون، مدیر عملیات هوش مصنوعی در موسسه سرطان Dana-Farber و “مشاهده نتایج مطالعات آزمایشی هوش مصنوعی MedPerf، که در آن همه مدلها بر روی سیستمهای بیمارستان اجرا میشدند، با استفاده از استانداردهای دادههای از پیش توافق شده، بدون اشتراکگذاری دادهها، هیجانانگیز است. یکی دیگر از رئیسهای گروه کاری پزشکی MLCommons در بیانیهای گفت. نتایج نشان میدهد که معیارها از طریق ارزیابی فدرال گامی در جهت درست به سوی پزشکی فراگیرتر با قابلیت هوش مصنوعی هستند.
MLCommons MedPerf را که در حال حاضر بیشتر به ارزیابی مدلهای آنالیز اسکن رادیولوژی محدود میکند، بهعنوان «گامی اساسی» به سوی مأموریت خود برای تسریع هوش مصنوعی پزشکی از طریق «رویکردهای باز، خنثی و علمی» میداند. از محققان هوش مصنوعی میخواهد تا از این پلتفرم برای اعتبارسنجی مدلهای خود در موسسات مراقبتهای بهداشتی و صاحبان دادهها برای ثبت دادههای بیماران خود استفاده کنند تا استحکام آزمایش MedPerf را افزایش دهند.
اما این نویسنده از خود میپرسد – با فرض اینکه MedPerf همانطور که تبلیغ میشود کار کند، که چیز مطمئنی نیست – آیا این پلتفرم واقعاً به مسائل غیر قابل حل در هوش مصنوعی برای مراقبتهای بهداشتی رسیدگی میکند یا خیر.
گزارش افشاگرانه اخیر که توسط محققان دانشگاه دوک گردآوری شده است، شکاف عظیمی را بین بازاریابی هوش مصنوعی و ماهها – گاهی سالها – زحمتی که برای به کار انداختن این فناوری به راه درست لازم است، نشان میدهد. این گزارش نشان میدهد که اغلب دشواری در یافتن چگونگی گنجاندن این فناوری در روال روزانه پزشکان و پرستاران و سیستمهای پیچیده مراقبت و ارائه خدمات فنی است که آنها را احاطه کرده است.
مشکل جدیدی نیست در سال 2020، گوگل وایت پیپری به طرز شگفت انگیزی منتشر کرد که دلایل کوتاهی ابزار غربالگری هوش مصنوعی برای رتینوپاتی دیابتی در آزمایش واقعی را شرح داد. موانع لزوماً به مدلها مربوط نمیشود، بلکه روشهایی است که بیمارستانها تجهیزات خود را به کار میگیرند، قدرت اتصال به اینترنت و حتی نحوه واکنش بیماران به ارزیابی به کمک هوش مصنوعی.
جای تعجب نیست که پزشکان مراقبت های بهداشتی – نه سازمان ها – احساسات متفاوتی در مورد هوش مصنوعی در مراقبت های بهداشتی دارند. یک نظرسنجی توسط Yahoo Finance نشان داد که 55٪ معتقدند این فناوری برای استفاده آماده نیست و تنها 26٪ معتقدند که می توان به آن اعتماد کرد.
این بدان معنا نیست که سوگیری مدل پزشکی یک مشکل واقعی نیست – این است و عواقبی دارد. برای مثال، سیستمهایی مانند Epic برای شناسایی موارد سپسیس، بسیاری از نمونههای این بیماری را از دست میدهند و اغلب هشدارهای نادرست صادر میکنند. همچنین این درست است که دسترسی به داده های پزشکی متنوع و به روز خارج از مخازن رایگان برای آزمایش مدل برای سازمان هایی که به اندازه گوگل یا مایکروسافت نیستند آسان نبوده است.
اما عاقلانه نیست که سهام زیادی را در پلتفرمی مانند MedPerf قرار دهیم که در آن به سلامت مردم مربوط می شود. در نهایت، معیارها تنها بخشی از داستان را بیان می کنند. استقرار ایمن مدلهای پزشکی مستلزم ممیزی مداوم و کامل از سوی فروشندگان و مشتریان آنها است – به غیر از محققان. فقدان چنین آزمایشی چیزی جز غیرمسئولانه نیست.
امیدواریم از این مقاله مجله نود و هشت زوم نیز استفاده لازم را کرده باشید و در صورت تمایل آنرا با دوستان خود به اشتراک بگذارید و با امتیاز از قسمت پایین و درج نظرات باعث دلگرمی مجموعه مجله 98zoom باشید
لینک کوتاه مقاله : https://5ia.ir/lcKKAP
 t_98zoom@ به کانال تلگرام 98 زوم بپیوندید
t_98zoom@ به کانال تلگرام 98 زوم بپیوندیدکوتاه کننده لینک
کد QR :







آخرین دیدگاهها